Rationale
With the Internet, tremendously rich parts of our cultural heritage could be freely accessible online. But most of them are still dormant (non-digitized collections) or disappearing (Web history).
Massive digital collecting, digitizing, and storage techniques make it possible to preserve and give public access to this rich material. Mastering these techniques will be key in the coming years for the future of cultural heritage, both traditional and materials produced in digital form.
Europe, cradle of a unique cultural heritage has a special role to play to this regard. But even in a connected world, propinquity, specific legal and technical environment should not be underestimated and having a European-based institution in this domain makes a difference.
By developing a large-scale archiving architecture in Europe and competences that come with it, the European Archive intends to be a catalyser in the development of skills and know-how in the domain of preservation and access to digital collections. It also intend to bring in Europe a new type of Cultural Institution that focus to free public access to large rich digital collections.
Web archiving
As the web has grown in importance as a publishing medium, we are behind in bringing into operation the archiving and library services that will provide enduring access to many important resources. Where some assumed web site owners would archive their own materials, this has not generally been the case. If properly archived, the Web history can provide a tremendous base for time-based analysis of the content, the topology including emerging communities and topics, trends analysis etc. as well as an invaluable source of information for the future.
The foremost effort to archive the Web has been carried on in the US by the Internet Archive, a non-profit foundation based in San Francisco. Every two months, large snapshots of the surface of the web are archived by the Internet Archive since 1996. This entire collection offers 500 terabytes of data of major significance in all domain that have been impacted by the development of the Internet, that is, almost all. This represent large amount of data (petabytes in the coming years) to crawl, organize and give access to.
non-profit foundation based in San Francisco. Every two months, large snapshots of the surface of the web are archived by the Internet Archive since 1996. This entire collection offers 500 terabytes of data of major significance in all domain that have been impacted by the development of the Internet, that is, almost all. This represent large amount of data (petabytes in the coming years) to crawl, organize and give access to.
By partnering with the Internet Archive, the European Archive is laying down the foundation of a global Web archive based in Europe.
Digitization
We have entered an era where digitization of all significant cultural artefacts will be completed. Within the next decade, most of the published cultural content (books, music, images and moving images) will have been digitized. Recent commercial announcements have fostered awareness and started this movement, but limited to a few major libraries which leaves an opportunity for an open system to be pursued. This entails digitizing, preserving and providing access to the rich public domain of books, music, images and moving images on a the large scale. By fostering the development of a large scale, archiving platform, the European Archive intend to facilitate the mastering of processes and tools needed for digital public content archiving and distribution in Europe.
Infrastructure
With the technical support of the Internet Archive and
XS4ALL, the European Archive has installed a repository with 250 terabytes (250 000 giga-bytes) capacity in Amsterdam via which a large collection digital material (text, music, moving images, software) can be accessed. On average, the download rate has been over 350 Megabits per second in December 2005, already making EA a significant content provider in Europe. The data organization is highly distributed (200 nodes on a cluster) to enable distributed processing. This achievement represents already a significant step in establishing in Europe an archiving infrastructure to collect and archive digital material at large scale. We plan to extent it to 1 petabyte (1000 terabytes) within the coming years.
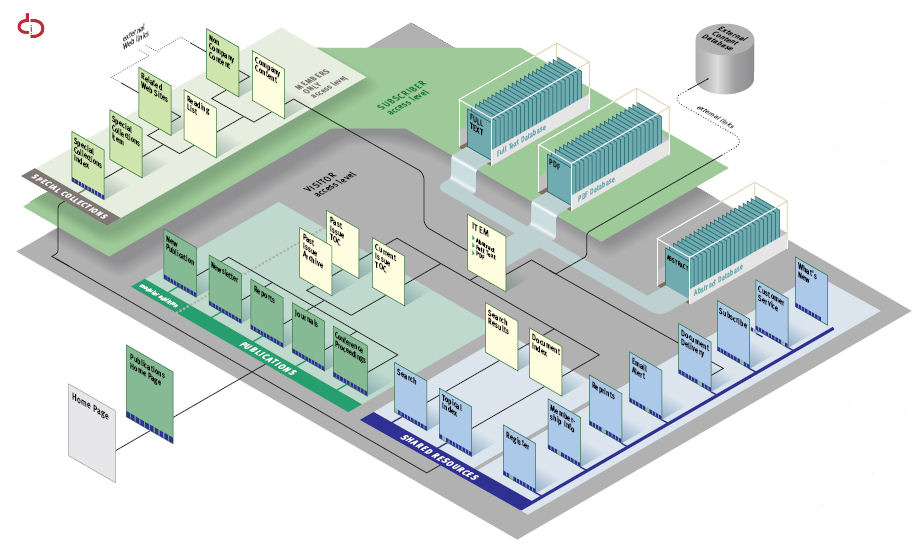
The European Archive should be accessible in Europe’s language. A multilingual web management system for large digital collections has been implemented. This system is based on a flat structure permanently indexed and updated. It allows light and flexible management of the web interface to collections, and can scale up unlimitedly in the future.
An opportunity for Europe
We expect the European Archive to become an essential piece in the European cultural heritage landscape. In order to meet the goals of Lisbon 2010 for Europe to become
“the most dynamic knowledge economy in the world”
large-scale public archive is a key component. It will enable public and free access to large portion of European cultural heritage and bring in the broadband network infrastructure tremendous quantity of rich and legal content. It will bring to traditional heritage institutions a technology partner enabling them to make significant steps towards digitization and public accessibility of their collections, making Europe more visible and attractive in a globally networked world. By developing cutting hedge technology application in the domain of massive digital collection acquisition, management and storage it will develop a centre of excellence in a key domain of tomorrow’s Internet.
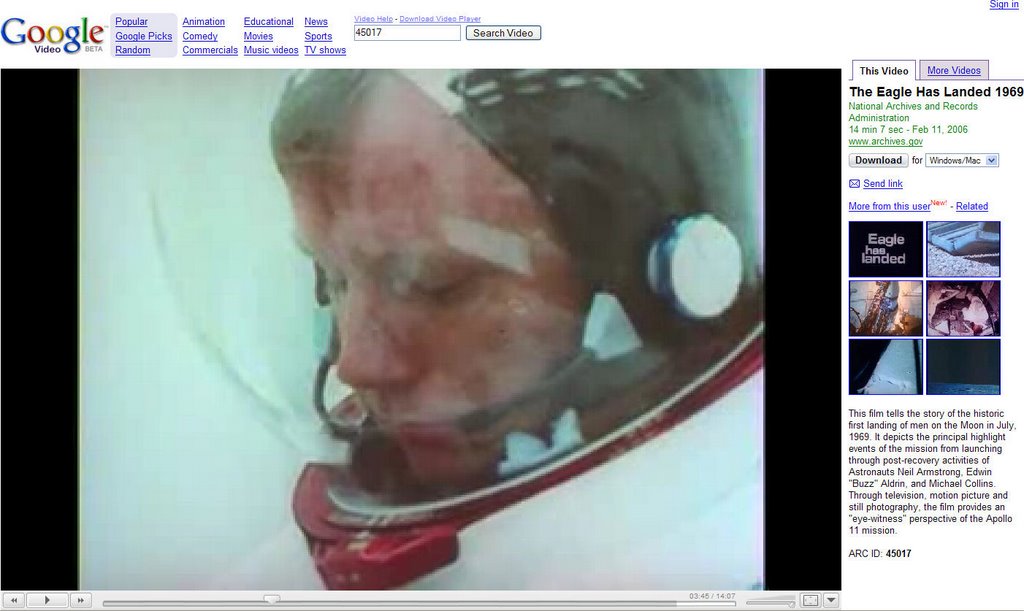
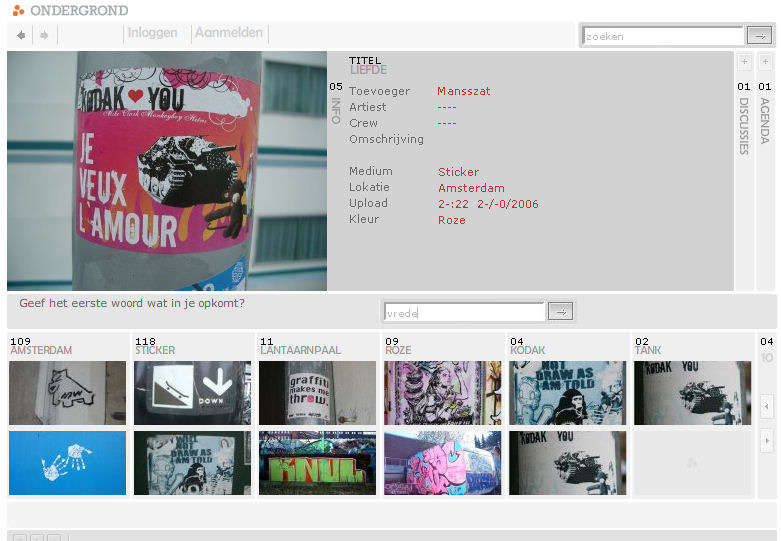
 Johan Oomen and I published our learnings in a magazine for Information Professionals. Johan being the projectleader at The Netherlands Institute for Sound and Vision and I being the information strategy consultant have been the tandem carrying out the project for the last 2 years.
The article is in Dutch, so is the magazine, but for the english readers we are aiming at presenting the story at the European Streaming Media conference in London on Octobre 12th-13nd.
Johan Oomen and I published our learnings in a magazine for Information Professionals. Johan being the projectleader at The Netherlands Institute for Sound and Vision and I being the information strategy consultant have been the tandem carrying out the project for the last 2 years.
The article is in Dutch, so is the magazine, but for the english readers we are aiming at presenting the story at the European Streaming Media conference in London on Octobre 12th-13nd.